TumblTwo - An Improved Fork of TumblOne, a Tumblr Downloader
Introduction
Note: New users should directly check out TumblThree. Over the last week I reverse engineered TumblOne by Helena Carver. The project is under Public Domain and thus free from copyright. Since there was no source code available and I always wanted to see how easily one can decompile .NET assembly and wanted to add new features, I thought I would give it a try and reflect it. Bonus: I’ve never touched C# before and this way, I could learn a new language on top.
There are other people on the projects discussion page that suggested similar features and since the development seemed stalled, I thought about releasing the code and the binary with my changes, thus probably also under public domain. I don’t want to take over the original project, nor infringe any copyright or claim fully authorship. So, if the original author wants to continue her project, I’d be happy to help and see my changes committed. For the meantime, I thought of a fork for the changes and a new project name.
TumblTwo, a TumblOne Fork
TumblTwo is an image downloader (crawler) for the Bloghoster Tumblr.com based on TumblOne. After supplying a url, the application will search and download all types of images in a given resolution. It’s possible to download only tagged images and download simultaneously from multiple blogs and enqueue others.
Screenshots:
Main UI, showing a list of blogs an top, the current queue status in the middle. On the right side are the control for managing the blogs and the crawl process: 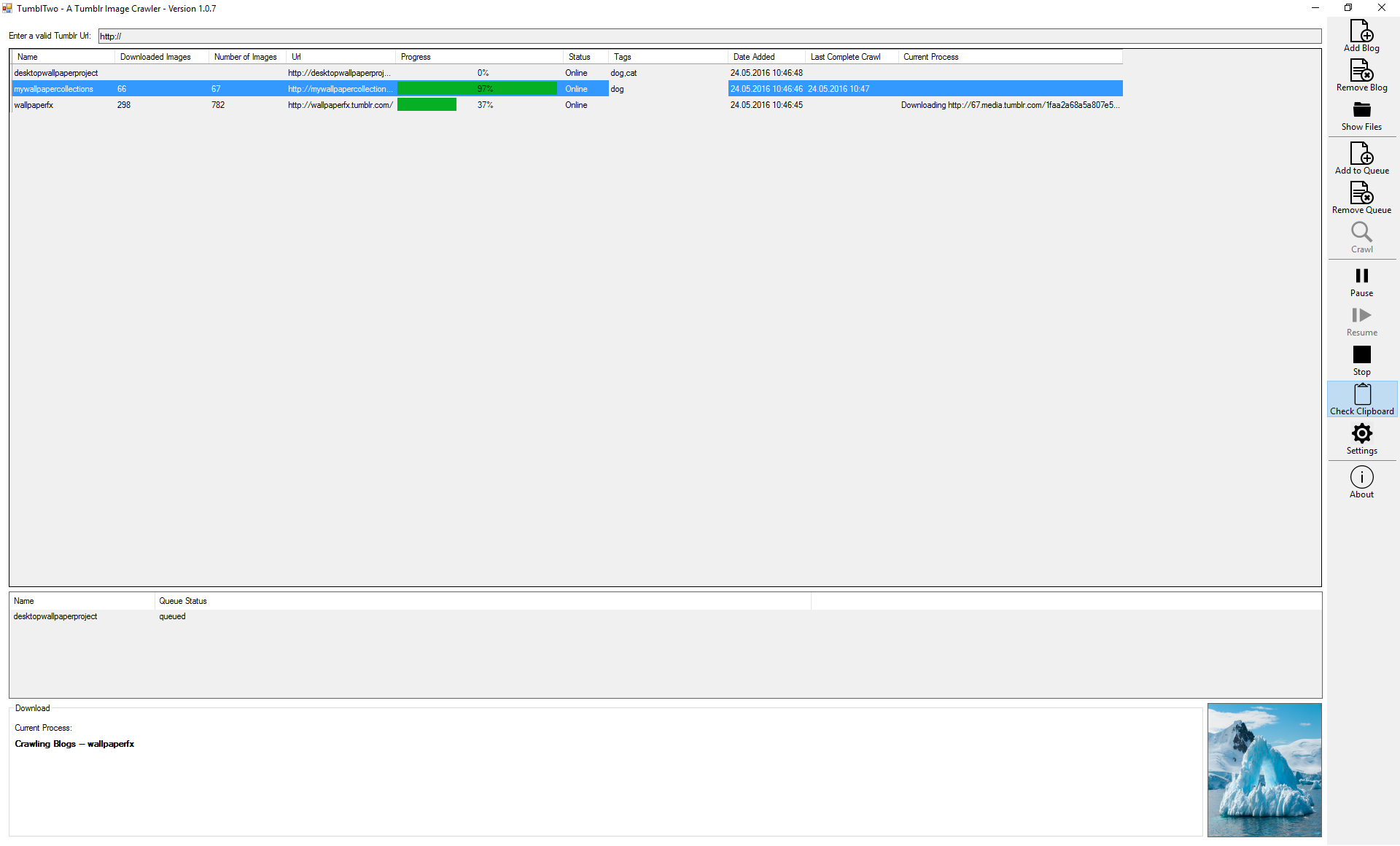
Program Usage
- To use the application, simply copy the url of any tumblr.com blog you want to download the pictures from into the textbox at the top. Afterwards, click on ‘Add Blog’ on the right.
- To start the crawl process, click on ‘Crawl’ on the right. The application will regularly check for (new) blogs in the queue and start processing them, until you stop the application by pressing ‘Stop’. So, you can either add blogs to the queue via ‘Add to Queue’ first and then click ‘Crawl’, or you start the crawl process first and add blogs to the queue afterwards.
- You can set up more than one parallel download in the ‘Settings’ on the right side. Also, it is possible to change the download location and the sizes of the pictures to download there.
Tags
- You can also download only tagged images by adding tags in a comma separated list in the tag column of the blog list in the top. For example: great big car,bears would search for images that are tagged for either a great big car or bears or both.
New Features
New Features (over TumblOne):
- multiple simultaneous picture downloads of a single blog, customizable in the settings. As an alternative, each picture is downloaded successively.
- multiple simultaneous downloads of different blogs, customizable in the settings.
- possible to download tumblr.com hosted videos.
- it is possible to download images from blogs only for specific tags.
- a clipboard monitor that detects http:// .tumblr.com urls in the clipboard (copy and paste) and automatically adds the blog to the bloglist.
- a download queue for blogs.
- a detection if the blog is still online or the owner has changed.
- the blogview is now sortable and shows more information, e.g. date added, last time finished and the progress.
- a settings panel (change download location, turn picture preview off/on, define number of simultaneous downloads, set the imagesize of downloaded pictures).
- Somewhat overhauled user interface which is resizable, faster and saves and restores its settings.
- Source code at github (Written in C# and WinForms).
Changelog
2016-06-10:
- Support for tumblr.com hosted videos. Check the settings window to enable video download (default: off).
- This is probably going to be the last release.
2016-05-24:
- New icons as it has been requested by the author of TumblOne.
- I am not the author nor owner of the website tumblone.com and not responsible for the content of this particular site.
2016-04-09:
- Support for urls starting with https: instead of http:
- The image preview now applies its visibility settings upon startup.
2016-04-04: Code Refactoring
- Started my complete code rewrite in C# using WPF and MVVM pattern. Most things are already done and set up but not debugged yet. Some converters for the UI are still missing. New features will be:
- Better and modular code!
- Internationalization support
- A blog rating system
- Save and restore, clear queuelist
- Movable items in queuelist
- Taskbar buttons and progress indicator
- Maybe it’s possible to add support for new websites now, and it’s certainly possible to add video support for tumblr.com hosted videos without a big hassle. CLI support and at some point i’m planing a mono gtk# UI for linux support. A screenshot showing the current state:
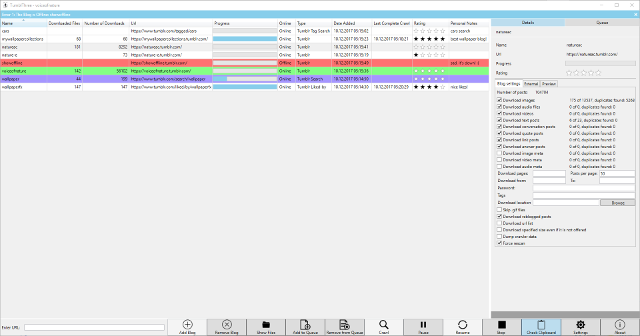
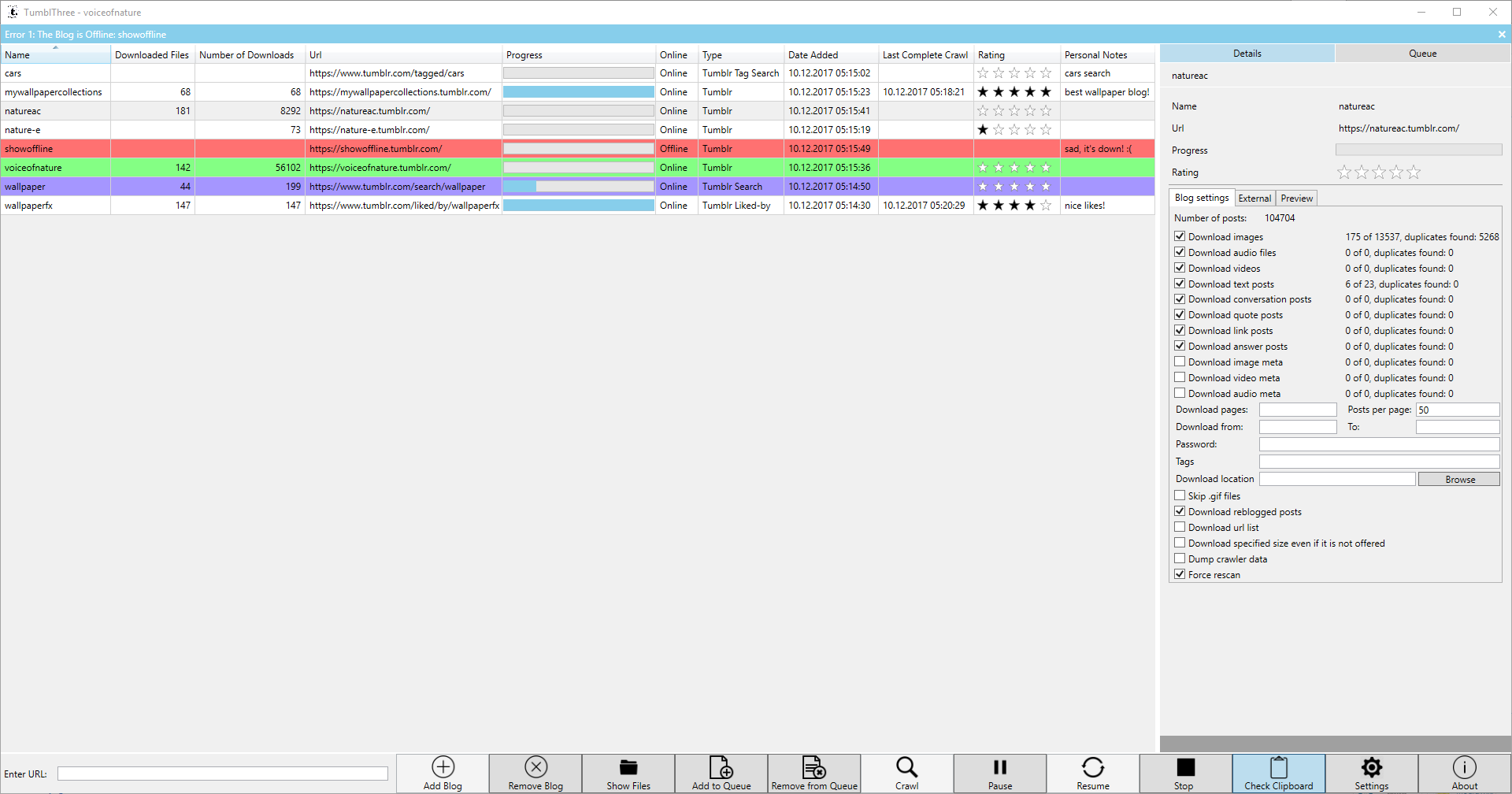
2016-03-11:
- Since we have to pre-crawl all image urls for the parallel image downloading, we now use its count for better progress indication instead of the total blog post count, which might contain double posts of the same image (seems to happen a lot), text, videos, etc..
2016-02-28:
- Version bump: Version 1.0.7.
- Some images were reloaded even if they were already downloaded since we have saved the full url and checked for duplicates using it. If the file however was hosted on a different mirror, the application would redownload the same file and increase the counter for downloaded images even if it was already downloaded.
- Finally, the program should work quite nice for everyone now I hope.
- Half finished mono release for Linux. It just runs and downloads, .. [GPG sig]
- Next Steps:
- I am going to upload a “mono” version for linux in a few hours/days without the clipboard monitor as it relays on windows 32 apis which seems to break the application. All the other stuff seems to work, after all the path handling in the code as been sanitized, thanks to \ and / in Windows and Linux, respectively
- Get rid of the progress indicators in the button as they are too troublesome for multiple blog downloads and provide similar or better information in the blog list at the top.
2016-02-27:
- Set a maximum degree of parallel downloads to prevent connection timeouts and connection closures from tumblr.com which appeared on my site after around 6,000-10,000 images. The crawl seemed stalled after a while, then finished before downloading all images. I’ve set the value to 50 20 and they are divided by the number of parallel blog downloads in the settings. When you crawl multiple blogs at once, you might have to adjust this value in the settings as it depends on your bandwidth. Thanks for the email regarding this issue!
2016-02-26:
- Further integrated the versions. The parallel crawl is now the default and integrated in the main TumblTwo.exe. You can switch to the old, serial download method in the Settings.
2016-02-25: stable releases
- Integrated the beta (tags) version into the main version, so no more “beta” right now. You add tags in the main blog list as comma-separated list e.g.: great big car, bears would search for images that are tagged for either a great big car or bears or both. Tags are saved and get reloaded if the blog was crawled for those once. Just clean the tags column to search for all images again.
- Clicking the picture preview in the bottom right corner opens a fullscreen preview. Upon clicking it, the normal view returns.
2016-02-24: stable releases
- I did a two day code cleanup to enhance and someday remove the wonky User Interface. The new versions aren’t compatible with the previous ones yet.
- the blog data is now mostly updated automatically without me messing around doing so manually. Thus this should greatly improve accuracy, amount of errors and remove lag
- the blogview now saves the column order, width and so forth. The Columns can be reordered.
- the blogview progress is now under layered with a progressbar.
- Probably more i already forgot. I am going merge the tags (beta)-version into this one and someday will come up with a new interface after reorganizing the code further. I just thought this might be a good intermediate version/step (for newcomers) as the UI should be more stable now, and the old versions are still here for download (since the data files are not compatible yet).
2016-02-22: all releases
- Further enhanced the parallel versions. We now generate an url list of all images in parallel and after its competition crawl in parallel over all images. At least here it vastly increases bandwidth, but the image downloads won’t start until all image urls are fetched.. Get them here: Windows Application (.exe) (~248 kb) [GPG sig] - Windows Application (.exe) (~248 kb) - Beta [GPG sig].
2016-02-19: all releases
- It’s now possible to download photosets.
- Added a detection if the blog is still alive and/or if its the same blog. Therefore we use the HTML Title and the blog description. I wasn’t sure if the title would be enough, since many blog titles are simply equal to the url, which might not change if the owner the blog changes. Thus, I’m also taking the description into account, but I’m not sure if they frequently change. So, I’m happy about any input in the comments/per mail about this if we’re generating too many false positives.
- A more parallelized version for single/few blog downloads can be found here: Windows Application (.exe) (~248 kb) [GPG sig] - Windows Application (.exe) (~248 kb) - Beta [GPG sig]. I haven’t yet much time to test it, but maybe it’s worth a try if you don’t download multiple blogs at once. The picture preview might lag/show nothing and the “stop/pause” won’t come at once since we “batch” download up to 50 images, but otherwise it should work.
2015-11-23: all releases
- Allows Column Sorting
- Added a process percentage column in the Blogview (no fancy progressbars yet).
- “Delete Blog” now deletes only the index file and removes the blog from the view, but does not delete any downloaded images.
2015-09-08: all releases
- It’s now possible to import TumblOne-Blogs by simply addind/moving the proper .tumblr files from the Index folder of TumblOne (which is also located inside the _\Blogs\_ folder which holds your downloaded pictures right next to where the TumblOne.exe is located) into the Index folder of your download location set in the ‘Settings’ window in TumblTwo. The blogs will be added but will be showing a “not yet crawled!”. Thats okay, because we use a different counting mechanism. After starting the first crawl, the proper index will be adjusted.
- For an update on video / larger image support, see here
2015-09-01: stable and beta release
- Removing a blog is now always possible and does not result in a reload of the whole library (not sure, why this was implemented in the first way.)
- Some fixes for the progressbar.
- Some minor UI code changes and cleanup.
2015-08-28: stable and beta release
- Added a Clipboard Monitor. Enabled by default, can be turned off in the mainwindow on the right side panel. Once turned on, if you ctrl-c or copy any text which contains one or more Tumblr blog urls, the blogs will be automatically added if they don’t exist.
- Disabled useless startup splashscreen.
2015-08-27:
- Beta release (Not really well tested yet). Crawl only specifically tagged images. Crawl only specifically tagged images by specifying the tags in the Queue Window in a comma separated way. I.e: Aston Martin,ferrari,Porsche. Consequently, the Blog is crawled for any image that matches the given tags. To do so: add the desired blog to the queue, without starting the crawl process. Now click in the cell next to the blog with the column header Tags for crawling. Enter your tags in a comma separated way, finish with enter. Start the crawl. If you don’t bother about tags, simply don’t add anything to crawl the whole blog.
2015-08-26:
- Fixed threading wonkiness. Sometimes, the queue still got depleted from idling tasks after pressing ‘stop’.
- Adjust the number of simultaneous downloads without a necessary restart of the application, if the number of threads is not smaller than it was before and if the crawl process is not currently running.
- Make sure the download location is always correct (trailing backslash) to fix the “The current blog cannot be saved to disk”-bug.
- Now saving the windowsize and its position.
2015-08-25:
- Large Speedup for startup times and resuming of blogs since we now catalogize all downloaded filenames together with their URLs in a small single index file, instead of checking for all single downloaded image files in the download folder at startup and which is now also used for duplication check. This should improve speed drastically. Also, its now possible to safely remove images out of the \Blogs\“MyDownloadedTumblrBlogFolder”\ without rendering in download them again, as long as you keep the .tumblr (index) file in the Index folder. This opens the way to a backup function.
- Specifying the number of Posts in each blogs. Might be equivalent to number of pictures, if the blog only contains pictures.
2015-06-04:
- Added Multiselection in the Blog and Queue View. To add multiple blogs at once to the queue, select the blogs with the ctrl-key or shift-key pressed, then hit “Add to Queue”. Same for removing, just in the “Queue”-view and hit “Remove Queue” (Thanks to Torn for suggesting this!).
2015-04-08:
- multiple simultaneous downloads
- a download queue
- a settings panel (change download location, turn picture preview off/on, define number of simultaneous downloads, set imagesize of downloaded pictures)
- the tumblrlist now features columns for ‘Date added’ and if and when the blog was completely crawled
- saves and restores settings
- resizable UI
Possible next Features (ToDo-List):
- prevent downloading “Image has been removed” / same images
- add a ‘expiration date’ to crawl only newer images in specific blog -> Partly done: You can simple recrawl all blogs, as long as you keep the Index (.tumblr) files, only newer images will be downloaded, since all images (the download url and the filename) are catalogized in the index file. No redownload occurs.
- option to automatically remove blogs when crawling is complete.
- batch input of tumblr blog urls from text file -> We check the Clipboard for URLs now. Simply ctrl-c your text file.
- import blog index files from TumblOne.
- ‘backup function’ for blog indexes -> Check your Downloadlocation\Index\ folder and save the appropriate .tumblr file for your specific blog.
- Download only specifically tagged files.
- proxy setting
- allow to download videos files.
- Download photosets
- Download inline images from other types than pictures posts (for example Question and Answers)
Bugs:
I’m completely new to C# and (safe)-threading programming and if anyone wants to help, feel free to commit. So, beware of the code ;). I’ll add source code annotations over the next few days and the first git commit is the pure reverse engineered TumblOne code without any modifications from my side.